
🍂 Questo post del 2010 viene riproposto a testimonianza dell’interesse che si iniziava a sviluppare in quegli anni nei confronti degli strumenti della statistica testuale.
Sembra strano oggi — mentre si discute di LLM e opinion mining — che iniziassi parlando di wordcloud: ai quei tempi, però, erano molto diffuse sul web e sui social media, e molto popolari.
Altra cosa che sembra bizzarra, è riferirsi ad un corpus di 15.000 token come “ampio”: oggi, con i modelli di linguaggio di grandi dimensioni, si parla di miliardi di token. Di fatto, però, i corpora fra i 10 e i 50mila token sono caratteristici ancora oggi dell’analisi del contenuto che si avvalga della statistica testuale.
Si tratta di campi di applicazione diversi, ed anzi solo in questi casi ha senso la questione che qui si pone del ruolo dell’interpretazione. In queste circostanze, è infatti possibile leggere i testi, valutare la qualità delle risorse lessicali, e quindi interpretare i risultati anche in chiave interpretativa. I corpora a cui si applicano le tecniche più moderne sono talmente grandi, che l’interpretazione umana diventa impossibile, e si deve fare affidamento su tecniche di validazione diverse.
Per ciò che riguarda il rapporto fra testo e contesto, è necessario oggi precisare che in questi casi l’approccio di elezione, quasi obbligato, è quello cosiddetto bag of words, ovvero un approccio che scompone il testo in singole parole (o token), ignorandone l’ordine e le relazioni grammaticali e sintattiche. Il ‘contesto’ viene così perso, e il testo è rappresentato semplicemente come un ‘sacco di parole’. Questa è la ragione che impone di selezionare testi omogenei (per qualche aspetto).
Gli approcci più moderni, come i modelli di linguaggio distribuzionali basati su embeddings o architetture Transformer, cercano invece di catturare il contesto analizzando le relazioni fra le parole. Tuttavia, questi modelli richiedono corpora di grandi dimensioni per funzionare in modo affidabile. Per le analisi di cui si parla in questo post, condotte su corpora di dimensioni limitate e dove l’interpretazione umana è centrale, l’approccio bag of words si rivela dunque non solo più trasparente e controllabile, ma anche tecnicamente più adeguato.
Per questo motivo, il post viene riproposto di seguito quasi senza modifiche.
Gli amanti dell’archeologia, troveranno il post originale in 🌍 The Wayback Machine
La statistica testuale – approccio all’analisi del contenuto che costituisce per molti versi l’erede naturale della classica semantica quantitativa, sviluppata fra gli anni Quaranta e gli anni Cinquanta negli Usa – viene utilizzata per analizzare il linguaggio e/o il contenuto di testi e documenti testuali con gli strumenti della statistica.
Esempi molto semplici di analisi quantitativa di un testo sono le wordclouds (nuvole di parole, o nuvole di frequenza), divenute familiari nel Web grazie ad applicazioni online come Wordle.net1, e Wordclouds.com che calcolano le frequenze delle parole presenti in un testo inserito dall’utente, e le rappresentano mediante grafici molto accattivanti.
Anche se la statistica testuale viene spesso contrapposta all’interpretazione (intesa come ermeneutica ), misure ed indici che forniscono una descrizione sintetica dei contenuti di un numero anche molto ampio di testi possono costituire un supporto affidabile per l’interpretazione.
Leggere è sempre interpretare
(Henry Miller)
Fra i diversi software dedicati a questo tipo di analisi, segnaliamo in particolare gli italiani TalTac e T-Lab . R offre diversi pacchetti dedicati , fra i quali i più noti sono tm e i recenti Quanteda e tidytext (quest’ultimo dedicato al text-mining). Lo stesso Atlas.ti prevede, così come altri software per l’analisi qualitativa computer assistita, alcune misure statistiche connesse alle frequenze delle parole contenute nei documenti del progetto.
Si tratta di software complessi da utilizzare, come complesse sono le tecniche statistiche e la lettura dei risultati prodotti. Prima di decidere se e in quali circostanze utilizzarli, per affiancare o sostituire l’analisi interpretativa, è opportuno quindi tenere conto di alcuni aspetti.
Testo e contesto
Tutte queste tecniche si basano sulla scomposizione dei testi in unità elementari di significato (le forme grafiche, cioè le parole e le espressioni composte quali ad es. “analisi_testuale”), e quindi come se il significato fosse veicolato da tali unità, e non anche dalle relazioni che si instaurano fra gli elementi che compongono il testo, ed in particolare fra il testo ed il contesto.
Ad esempio, è difficile articolare il senso di una wordcloud in quanto le relazioni delle parole fra di loro e con il loro contesto non sono rappresentate.
La statistica testuale consente oramai di andare molto oltre il semplice conteggio delle frequenze, e anche di recuperare, almeno in parte, il rapporto fra la parola e il testo nel quale è inserita, così come anche le relazioni delle parole fra di loro, con l’analisi di associazioni (Fig. 2), co-occorrenze, analisi tematiche, e molto altro (rimando a questo testo di Francesca Della Ratta, dal quale è peraltro tratta la wordcloud nell’immagine precedente).
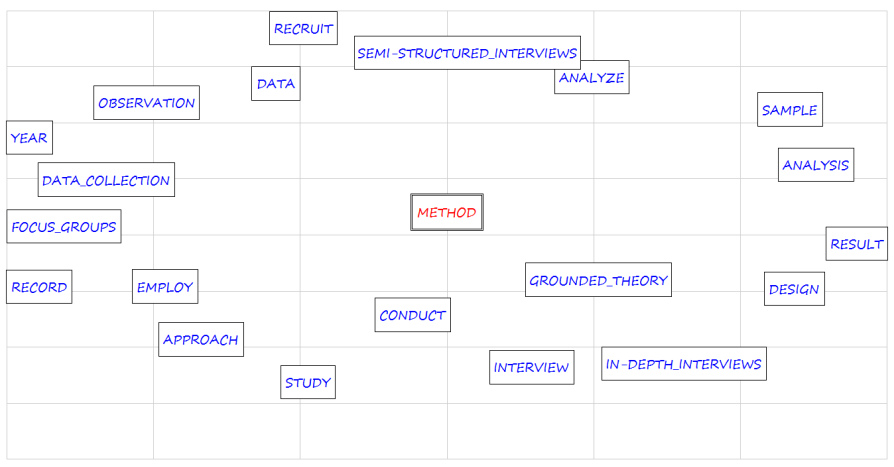
Grafico delle associazioni fra il termine ‘Method’ e gli altri termini contenuti negli abstracts degli articoli sulla Grounded Theory. I termini più vicini mostrano le associazioni più forti.
Non si sommano le mele con le pere
Poiché misure e indici hanno un valore solo ed esclusivamente rispetto alle parole contenute nei testi, queste tecniche andrebbero applicate ad un corpus non solo ampio ma anche omogeneo: ampio (almeno 15.000 occorrenze) affinché gli indici statistici siano basati su un numero consistente di occorrenze; omogeneo, perché i risultati siano interpretabili sul piano sostantivo.
I testi inclusi nell’analisi dovranno cioè essere omogenei sia sul piano formale sia su quello dei temi trattati, in modo da garantire (a priori) che i termini in analisi possano essere attribuiti ad un certo campo semantico. I testi dovrebbero insomma parlare di uno stesso argomento, e/o appartenere ad uno stesso contesto, e/o essere stati prodotti da uno stesso autore.
Se può essere facilmente comprensibile il senso dell’analisi statistica delle opere di un singolo autore (ad esempio l’opera di Shakespeare ), più problematica può essere la lettura dei risultati dell’analisi di un corpus composto da tanti articoli di giornale, o da diversi messaggi pubblicitari. Non potrebbe essere che autori diversi, o testate diverse, risultino non comparabili dal punto di vista del linguaggio utilizzato?
Più in generale, si pone anche il problema della definizione dei criteri che definiscono l’omogeneità dei testi: stesso autore, stesso argomento, stessa parola chiave, risposte diverse alle stesse domande, ecc.
Bisogna infine ricordare che la statistica non garantisce in quanto tale l’“oggettività” dei risultati. Quanto sin qui detto, infatti, dovrebbe lasciar intuire che i fattori “soggettivi” e contestuali (le decisioni del ricercatore cioè, così come il contesto della stessa produzione dei testi) svolgono pur sempre un ruolo determinante. Bolasco suggerisce infatti di utilizzare l’espressione analisi semi-automatica dei testi.
È infatti il ricercatore scegliere i testi da analizzare, a valutarne l’omogeneità, e ad operare su di essi i molti necessari interventi da effettuare prima dell’analisi.
La stessa lettura dei risultati di solito non è scontata ed auto-evidente (né del resto potrebbe mai essere auto-evidente qualcosa di prodotto attraverso procedure tanto complesse). A partire quindi dagli stessi testi, anche con la statistica testuale, ricercatori diversi potrebbero giungere a risultati e conclusioni diversi.
Resta dunque preferibile (in base anche al semplice buon senso) integrare laddove opportuno e possibile i diversi strumenti, e soprattutto evitare di utilizzarli a sproposito, come non di rado accade.
Riferimenti bibliografici
Berelson, B., & Lazarsfeld, P. F. (1948). The analysis of communication content. Universitetets studentkontor.
Bolasco, S. (2013). L’analisi automatica dei testi: Fare ricerca con il text mining. Carocci.
Della Ratta - Rinaldi, F. (2009). L’analisi testuale computerizzata. In L. Cannavò & L. Frudà (A c. Di), Ricerca sociale: Tecniche speciali di rilevazione, trattamento e analisi (pagg. 133– 152). Carocci.
Ježek, E., & Sprugnoli, R. (2023). Linguistica computazionale: Introduzione all’analisi automatica dei testi. Il Mulino.
Silge, J., & Robinson, D. (2017). Text Mining with R: A Tidy Approach. O’Reilly Media.
-
Wordle non è più disponibile, ma ero lo strumento che andava per la maggiore, ai tempi. La wordcloud che vedere sopra è stata generata con Wordle. ↩︎