maggio 2025
Esempio Sepolcri
Testo e corpus
Con il termine “testo” indichiamo l’insieme delle parole che compongono uno scritto (documento).
L’insieme dei testi oggetto di analisi viene definito corpus (pl. corpora)
Il testo dell’esempio illustrato in questo capitolo è quello dell’ode I Sepolcri, così come disponibile in WikiSource, e di cui riportiamo solo la prima strofa.
All’ ombra de’ cipressi e dentro l’ urne
Confortate di pianto è forse il sonno
Della morte men duro? Ove più il Sole
Per me alla terra non fecondi questa
Bella d’ erbe famiglia e d’ animali,
E quando vaghe di lusinghe innanzi
A me non danzeran l’ ore future,
Né da te, dolce amico, udrò più il verso
E la mesta armonia che lo governa,
Né più nel cor mi parlerà lo spirto
Delle vergini Muse e dell’ Amore,
Unico spirto a mia vita raminga,
Qual fia ristoro a’ dì perduti un sasso
Che distingua le mie dalle infinite
Unità di contesto: documenti e frammenti
La statistica testuale si basa sull’analisi e il trattamento delle co-occorrenze fra parole. Ma cosa si intende per “co-occorrenza” o “vicinanza” di due parole? Nel nostro esempio, le parole “ombra” del primo verso e “risplenderà” dell’ultimo co-occorrono? Sono vicine o sono lontane?
Per dare una risposta sensata a domande di questo genere, è necessario prendere alcune decisioni sul contesto delle parole: l’ode, la strofa, le opere di Foscolo, ecc.
I testi potranno dunque essere segmentati in frammenti, che saranno le unità di contesto rispetto alle quali saranno valutate molte delle misure statistiche utilizzate.
Nel caso del nostro esempio, abbiamo diviso il testo originale in frammenti corrispondenti alle frasi (divise da segni di interpunzione forti). Si considerino i primi tre:
## Corpus consisting of 3 documents. ## sepolcri.txt.1 : ## "All' ombra de' cipressi e dentro l' urne Confortate di pianto è forse il sonno ..." ## ## sepolcri.txt.2 : ## "Ove più il Sole Per me alla terra non fecondi questa Bella d' erbe famiglia e d'..." ## ## sepolcri.txt.3 : ## "Vero è ben, Pindemonte!"
Unità di analisi: parole, token e type
Le prime domande che solitamente si pongono a livello descrittivo sono: quanto è lungo il testo? Quante parole contiene? Quali sono le parole più frequenti?
Una prima risposta può essere data contando i caratteri del testo:
## sepolcri.txt ## 10929
Il numero di caratteri può essere conteggiato tenendo conto o meno degli spazi (il numero precedente li incluse).
Ancora meno immediato è definire cosa significhi “lunghezza” in termini di “parole”.
- il token è la singola occorrenza o replica di un type;
- il type è il tipo di occorrenza scandita dal parsing del testo … “. I type vengono anche chiamati forme (grafiche) o grafie.
Le parole, comunemente intese, sono i token esclusi i segni di punteggiatura, mentre la frequenza di una parola è il numero di occorrenze del type.
## Corpus consisting of 1 document, showing 1 document: ## ## Text Types Tokens Sentences ## sepolcri.txt 1096 2363 56
Per estensione o ampiezza in occorrenze di un testo intendiamo l’insieme dei token (2363), mentre 1.096 è l’ampiezza del suo vocabolario (\(V\)).

Numero di ‘parole’ nei segmenti
Tokenizzazione
Le parti di un testo oggetto dell’analisi lessicale sono solitamente le parole, ma per tokenizzazione può intendersi anche la suddivisione di uno o più testi in lettere o caratteri, linee, sequenze (n-grammi), frasi, paragrafi e frammenti di testo di lunghezza e definizione arbitraria (i segmenti).
I confini delle parole sono convenzionalmente rappresentati dagli spazi che li dividono e dai segni di punteggiatura.
I tokens della frase All’ombra de’ cipressi e dentro l’urne Confortate di pianto sono:
## Tokens consisting of 1 document. ## text1 : ## [1] "All" "ombra" "de" "cipressi" "e" ## [6] "dentro" "l" "urne" "Confortate" "di" ## [11] "pianto"
Trattamento del lessico e normalizzazione
Un ulteriore intervento di normalizzazione dei testi, dopo le correzioni ortografiche in fase di pre-trattamento, avviene quindi in fase di tokenizzazione, e riguarda:
- numeri;
- segni di punteggiatura;
- simboli, quali “#” e “$”.
Inoltre, è possibile normalizzare le parole in modo da ridurre il numero di forme grafiche distinte, ad esempio, riconducendo cosa e cose alla forma base cosa, o casa e case alla forma base casa. Questo processo si chiama come lemmatizzazione.
Nelle analisi testuali e del contenuto, vengono solitamente (non sempre) applicate altre procedure di riduzione/normalizzazione delle forme grafiche, che servono ad aumentare la coerenza del lessico:
- l’eliminazione delle parole vuote, o stopwords: parole vuote prive di un significato autonomo, come gli articoli o le congiunzioni;
- il trattamento delle maiuscole;
- la disambiguazione di termini con la stessa grafia (ad es. “stato” e “Stato”);
- l’individuazione e il trattamento dei poliformi, o multiword (come “Presidente della Repubblica”, o “anche se”);
- il trattamento delle forme flesse (stemming o lemmatizzazione).
- l’eliminazione di forme grafiche che non sono parole, come i numeri e le sigle (ad es. “R.S.I.” o “U.S.A.”).
Le parole vuote
Le 15 forme più frequenti dei Sepolcri, non sono significative dal punto di visto del contenuto, essendo tutte articoli, preposizioni e congiunzioni, ovvero parole vuote (stopword).

I Sepolcri. Le quindici forme più frequenti
Il testo del primo segmento dei Sepolcri è:
“All’ ombra de’ cipressi e dentro l’ urne Confortate di pianto è forse il sonno Della morte men duro?”
I token, esclusa la punteggiatura, sono:
## Tokens consisting of 1 document. ## sepolcri.txt.1 : ## [1] "All" "ombra" "de" "cipressi" "e" ## [6] "dentro" "l" "urne" "Confortate" "di" ## [11] "pianto" "è" "forse" "il" "sonno" ## [16] "Della" "morte" "men" "duro"
Tolte le maiuscole e le stopword, abbiamo:
## Tokens consisting of 1 document. ## sepolcri.txt.1 : ## [1] "ombra" "cipressi" "dentro" "urne" "confortate" ## [6] "pianto" "forse" "sonno" "morte" "men" ## [11] "duro"
Infine, dopo aver ridotto le forme flesse (in questo caso con la lemmatizzazione), il testo risulta normalizzato in questo modo:
## Tokens consisting of 1 document. ## sepolcri.txt.1 : ## [1] "ombra" "cipresso" "dentro" "urna" "confortare" ## [6] "pianto" "forse" "sonno" "morte" "men" ## [11] "duro"
Alla fine di questo processo, i 15 lemmi più frequenti sono:

I 15 lemmi più frequenti
Frequenze
Completati questi passaggi, abbiamo una matrice delle forme normalizzate, a partire dalle quali è possibile costruire distribuzioni di frequenze e grafici.
## Document-feature matrix of: 56 documents, 782 features (97.52% sparse) and 0 docvars. ## features ## docs ombra cipresso dentro urna confortare pianto forse sonno morte ## sepolcri.txt.1 1 1 1 1 1 1 1 1 1 ## sepolcri.txt.2 0 0 0 0 0 0 0 0 1 ## sepolcri.txt.3 0 0 0 0 0 0 0 0 0 ## sepolcri.txt.4 0 0 0 0 0 0 0 0 0 ## sepolcri.txt.5 0 0 0 0 0 0 0 0 0 ## sepolcri.txt.6 0 0 0 0 0 0 1 0 0 ## features ## docs men ## sepolcri.txt.1 1 ## sepolcri.txt.2 0 ## sepolcri.txt.3 0 ## sepolcri.txt.4 0 ## sepolcri.txt.5 0 ## sepolcri.txt.6 0 ## [ reached max_ndoc ... 50 more documents, reached max_nfeat ... 772 more features ]
Anche le wordcloud risulteranno più significative se costruite con un numero ridotto e selezionato di lemmi.

I Sepolcri: wordcloud dei 35 lemmi più frequenti
Co-occorrenze
## Feature co-occurrence matrix of: 782 by 782 features. ## features ## features ombra cipresso dentro urna confortare pianto forse sonno morte men ## ombra 0 1 1 3 1 1 2 1 1 1 ## cipresso 0 0 1 2 1 1 1 1 1 1 ## dentro 0 0 0 1 1 1 1 1 1 1 ## urna 0 0 0 0 1 1 1 1 1 1 ## confortare 0 0 0 0 0 1 1 1 1 1 ## pianto 0 0 0 0 0 0 1 1 1 1 ## forse 0 0 0 0 0 0 0 1 1 1 ## sonno 0 0 0 0 0 0 0 0 1 1 ## morte 0 0 0 0 0 0 0 0 0 1 ## men 0 0 0 0 0 0 0 0 0 0 ## [ reached max_nfeat ... 772 more features, reached max_nfeat ... 772 more features ]
Le co-occorrenze vengono elaborate ricorrendo diverse misure di associazione, similarità o distanza.
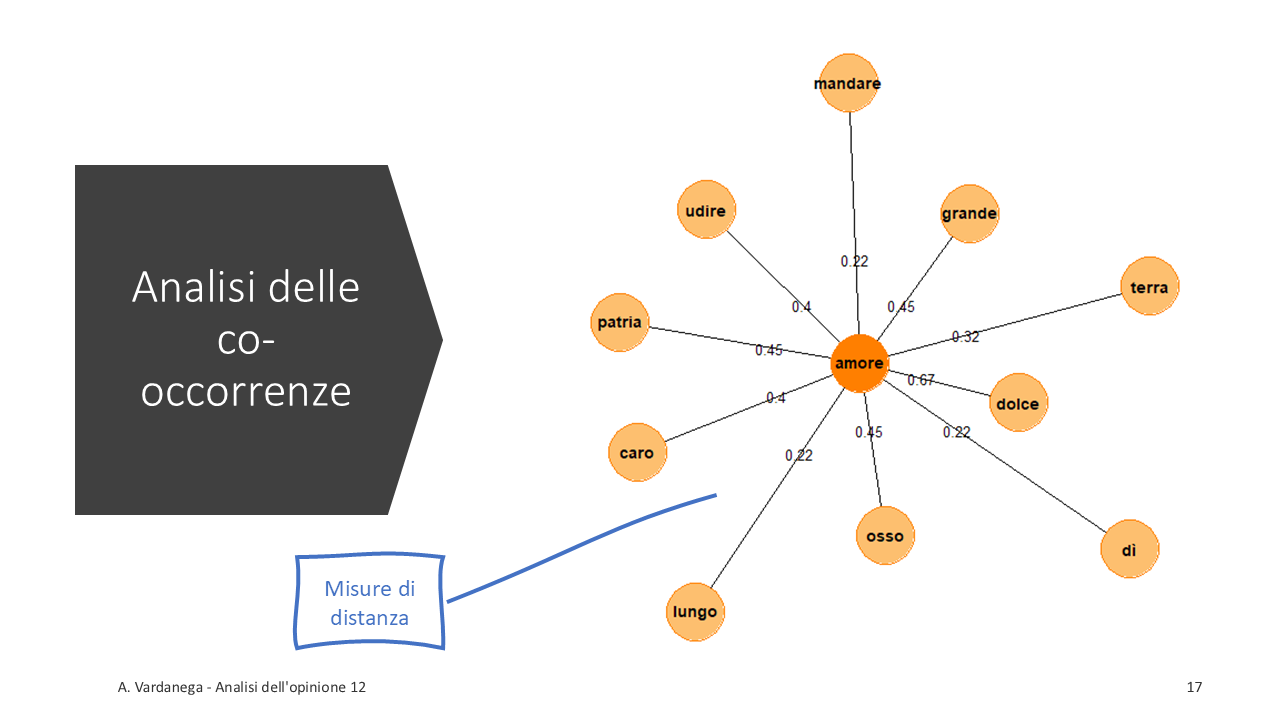
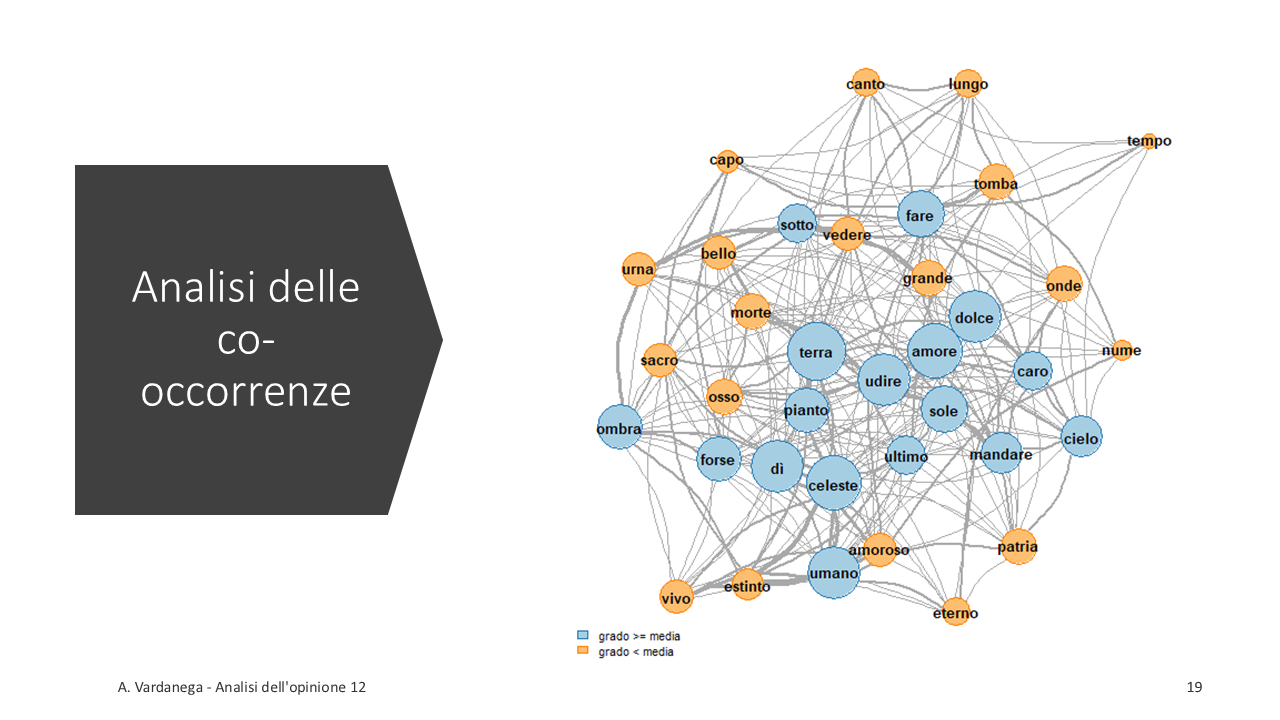
MDS multidimensional scaling.

Multidimensional Scaling